Understanding Machine Learning and its Basic WorkFlow
The basic workflow in Machine Learning for any aspiring Data Scientist or Machine Learning Engineer.

Introduction
Technology has taken a tremendous role in our day-to-day life where we do almost everything with the help of technology; from household chores to workplaces and also in commercial organizations. We are currently in the dawn of a new age, The Age of AI, Artificial Intelligence.
What is AI? It is a term that has taken the headlines day after day.
Back in the 1950s, the fathers of the field, Minsky and McCarthy, first coined the term artificial intelligence as any task performed by a machine that would have previously been considered to require human intelligence.
That’s a fairly broad definition, which is why you will sometimes see arguments over whether something is truly AI or not.
Modern definitions of what it means are more specific. Francois Chollet, an AI researcher at Google and creator of the machine-learning software library Keras, has said Artificial intelligence is tied to a system’s ability to adapt and improvise in a new environment, to generalize its knowledge, and apply it to unfamiliar scenarios.
From AI came buzz words like Machine Learning and Neural Networks.
Here we’ll focus more on Machine Learning.

According to Arthur Samuel who first coined the term Machine Learning, he stated that machine learning is the field of study that gives the computer ability to learn without being explicitly programmed. He also added: “Programming computers to learn from experience should eventually eliminate the need for much of this detailed programming effort” Samuel, A. L. (1959) which has been unfolding day after day.
Machine learning is an important tool for the goal of leveraging technologies around artificial intelligence. Because of its learning and decision-making abilities, machine learning is often referred to as AI, though, in reality, it is a subdivision of AI.
To get more in-depth on the branches of AI, consider visiting AnalyticStep for more detailed information.
ML has become a necessary aspect of modern business and research for many organizations today. It uses algorithms and neural networks (which we’ll not get into depth) models to assist computer systems in progressively improving their performance. ML algorithms learn from sample data — also known as “training data” — to make decisions without being explicitly programmed to make those decisions.
What’s the difference between Machine Learning and Traditional Programming?
** Note: Traditional programming is also referred to as ‘Software 1.0’ while Machine Learning is also referred to as ‘Software 2.0'

The major difference is that in traditional programming, the user gives the input to a program then states some steps (rules/instructions) for a program to accomplish a given task while in Machine Learning, the user gives the algorithm both the input and the output, then the algorithm figures out the patterns (in the given data) and is capable of giving prediction when given a different value as the input.
Secondly, 1.0 requires 2.0; why? Software 1.0 uses traditional disciplines which are also applied in Software 2.0.

Machine Learning is wide but looking at its basic workflow, data is the main component of Machine Learning. “Data is the new oil”- Kai-Fu Lee. Without the data, we cannot have machine learning models for the models have to learn from the existing data, find patterns, and then give a prediction from ‘unseen’ data.
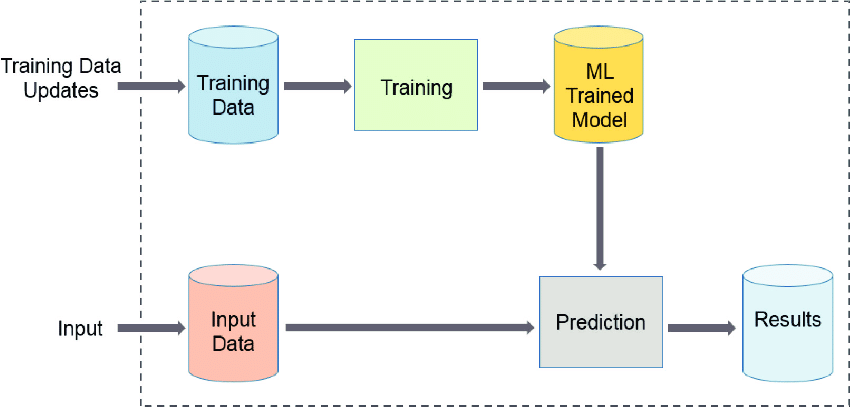
Data, being the major component, one must consider having a modicum of extra attention when handling it(Data wrangling); from imputation(filling of missing values), feature encoding(conversion of categorical values to numerical values)…etc. This is because a slight misinterpretation will automatically lead to having an inappropriate model.

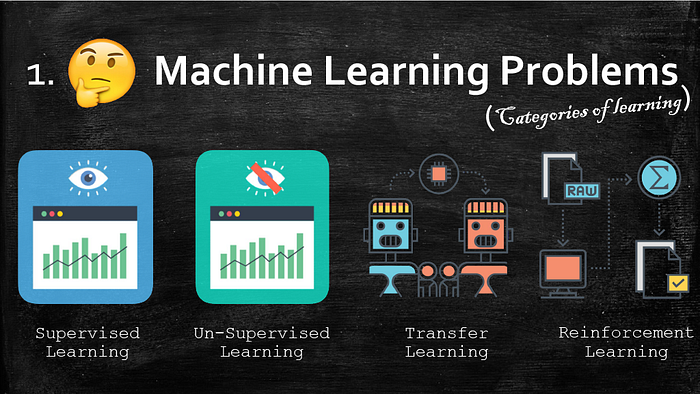
1. Machine Learning Problems
“How do Machine Learning problems look like?”
I have categorized Machine learning problems into two: 1. Categories of learning, 2. Problem Domains.
Categories of Learning
Supervised learning is an approach where a computer algorithm is trained on input data that has been well labelled for a particular output which means the data is already tagged with the correct answer. After that, the model is provided with a new set of data so that the supervised learning algorithm analyses the data and produces the ‘correct’ labelled output.

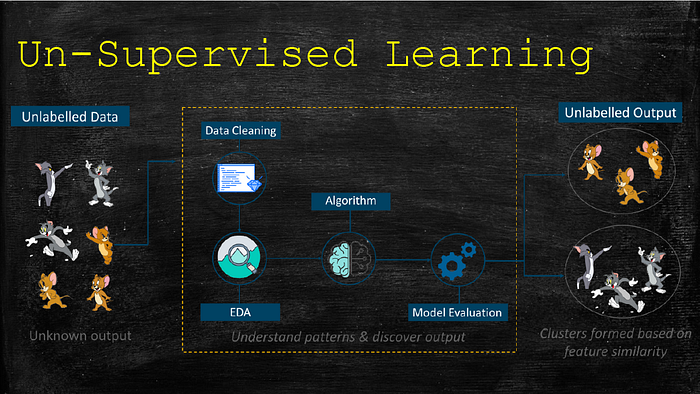
Un-Supervised learning is an approach where a computer algorithm is trained on unlabelled input data hence finding the patterns in the data. After that, when the model is provided with a new set of data, it clusters together related labels based on the patterns it has discovered from the training data.
Transfer learning is a deep learning technique that enables developers to avoid creating a neural network model from scratch but instead harness a neural network used for a task and apply it to another domain by possibly tweaking the last layers of the neural network.
An example is that one can have a model that identifies the images of dogs and wants to create one that identifies the images of cars. With transfer learning, you begin with the already existing neural network(CNN)- (commonly used for image recognition); the one being used to identify images of dogs, and then you tweak it to train with cars.
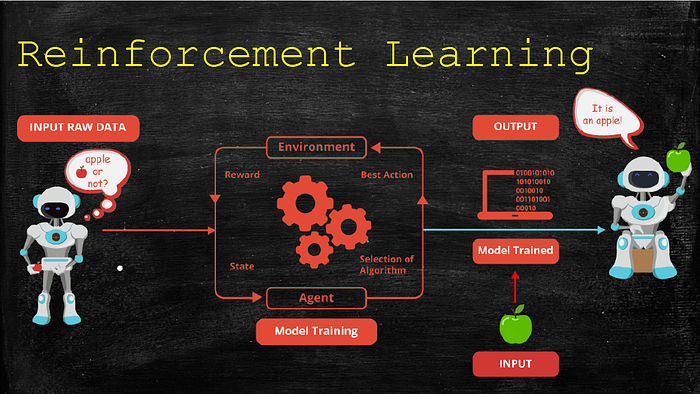
Reinforcement Learning is a machine learning technique that focuses on training a model based on reward and punishment. Positive feedback from a model leads to a reward while negative feedback leads to punishment for making a mistake or going against the expectation. Imagine training a child on how to come home early. When the child arrives home early, the parent can buy the child a present (reward) but when the child comes home late, the parent will not buy the child a present (punishment). This will make the child come home early frequently to increasingly receive presents. In the same way, the key goal of the reinforcement learning algorithm is to maximize on rewards hence making the model learn from its successes and failures.
Problem Domains

Focusing on problem domains, we have five(5) main categories:
1. Classification problem, 2. Regression problem, 3. Clustering, 4. Dimensionality reduction, 5. Sequence to sequence.
Classification Problem would be like answering the question ‘does someone has heart disease or not based on their medical records?’ This means that it returns a discrete value. Classification is further subdivided into Binary classification, Multi-class classification, and Multi-label classification.
Regression Problem would be like answering the question ‘what is the price of this house? The output will be a number’. This means that it returns a continuous value or a number.
Clustering -Used to find out how many groups there are…; for example, what types of songs are people listening to more on Spotify based on the music genre.’ Hence, you will cluster the number of people who listen to pop music, another cluster for the people who listen to house music, another for people who listen to gospel, reggae…etc
Dimensionality Reduction occurs when one has a huge amount of data where a model can’t find any patterns because there is just too much of it. Due to this, dimensionality reduction tries to reduce some of the data present to only pull out the most important details in the data.
Sequence to sequence(seq2seq) Sequence to sequence models is a special class of Neural Networks(RNN) that is typically used to solve complex language problems like Machine Translation, Question Answering, Creating Chatbots, Text Summarization, etc. For example, having a model that you give a sequence of English text, and translate it to french or like having a conversation with Alexa.
2. Machine Learning Process
As we stated earlier concerning the data, the machine learning process starts from ‘the data’, what do I mean? Data Collection…

a) Data Collection
What data exists? Where can it be found or where can I get it? Is it public or are there privacy concerns? Is it structured or unstructured?
Collecting data for training the ML model is the basic step in the machine learning pipeline. The predictions made by ML systems can only be as good as the data on which they have been trained, hence one should, (as stated earlier) consider having a modicum of extra attention when handling it. The data collected, on many occasions, is never clean and problems can arise in the process of collecting the data. These include inaccurate data, missing values in the data, and also biased data where the model could propagate inherent biases on gender, politics, age, or region.
(We’ll look at these problems and techniques that can be applied to address them in depth in the next article)
b) Data Preparation
Data preparation starts with Exploratory Data Analysis (EDA) where one first learns about the data he/she is working with. At this stage, one finds answers to questions like What are the feature variables(input) and the target variables(output)? Is the data structured, unstructured, categorical, numerical…? Are there missing values in the data? Are there outliers? And most importantly, a point that many forget to consider is, Are there questions you could ask a domain expert about the data? eg. a heart disease physician when dealing with a heart disease set of data.
Real-world data is often incomplete and inconsistent. It is also likely to contain many errors. So, data preparation is key before training a model with it. Hence, emerges the term data pre-processing where the data is ‘pre-processed’ into a format that when it is ‘fit’ in the model, the machine learning algorithm can easily find patterns from it.
Data pre-processing involves several techniques including data cleaning, imputation(filling of missing values), feature encoding(converting categorical values in the data to numerical), feature normalization, dealing with imbalances … etc. (We’ll get into depths in the next article).
Data splitting also occurs in data preparation where first the data set is split into features(X) and labels(y) then split further into training and testing sets.
C) Training a Model
After data has been processed and ‘seiving’ has taken place, we can now train our model from the data and see whether it can find patterns from it.
The first factor to consider before training a model is the type of algorithm to use (also known as an estimator). Different estimators are better suited for different types of data and different problems hence one should answer the questions: What problem am I trying to solve and what type of data do I have?. In that regard, Scikit-learn has provided an awesome flowchart on how to choose the right estimator.
D) Analysis/Evaluation
This step is particularly important to compare how well different models perform on a particular dataset on the unseen data. By using different metrics for performance evaluation, one should be in a position to improve the overall predictive power of the model before it is rolled out for production on unseen data. Without doing a proper evaluation of the ML model using different metrics, and depending only on the current accuracy of the model, it can lead to a problem when the respective model is deployed and used on unseen data hence can result in poor predictions.
E) Deploying a model
This involves putting the model into production. Evaluation metrics are great but until the model is in production, one won’t know how it performs in the real world.
3. Machine Learning Tools
I know the problem and the process to find the solution but, which tools am I gonna use in building the solution?
Machine Learning tools are several and it is not a rule for one to know them all at once to become a Machine Learning Engineer or Data Scientist. One encounters them one after the other while still on the learning curve. They are classified into several groups which will be discussed in depth in a different article:

4. Machine Learning Mathematics
Mathematics in ML is a key concept that explains ‘what is happening under the hood’ when one writes an ML code. The mainly used mathematical concepts include Linear Algebra, Matrix Manipulation, Multivariate Calculus, Optimization… etc.

5. Machine Learning Resources
Finally, “I have just fallen in love with Machine Learning. Just saw the several problems it’s gonna solve and revolutionize the industries in unimaginable ways but how or where can I find help; how can I start my Machine Learning journey?”… Best Answer: Google haha…

Everything on Machine Learning has been documented on different sites on Google which includes the complete Machine Learning Roadmap. Google is the best resource to start with but in addition to research on Google, there are platforms like Coursera, Udacity, Codecademy, Khan Academy, Simplilearn,… etc. where one can learn the skills, not forgetting YouTube, one of the best free resources to utilize.
Wanna get into Data Science; find my article: The Ultimate Guide to Getting Started in Data Science and get some insights on how to get started in the field of Data Science and how Machine Learning and Data Science relate.
What Next?… Till next time; bye-bye…
